在時序資料前處理中,smoothing為最常見的一個資料前處理的步驟,其目的在於移除資料中的干擾(noise),期望找到長期(long-term)的特徵並減少短期(short-term)訊號影響。常使用的方法為移動平均(moving average),為利用統計方法將依定時間內的數值加以平均,並將不同時間所獲得的平均值連接在一起。
簡單移動平均(Simple moving average, SMA)
其中n為窗口大小,SMA_t(n)為時間點t的移動平均值
加權移動平均(Weighted moving average, WMA)
與簡單移動平均相似,但在計算平均數值並不是每個時間點都給予相同權重,而是以最近的觀察值更大的權重。
指數平滑移動平均(Exponential moving average, EMA)
為加權移動平均的其中一種,會以一固定指數遞減數列作為各個時間點的權重。
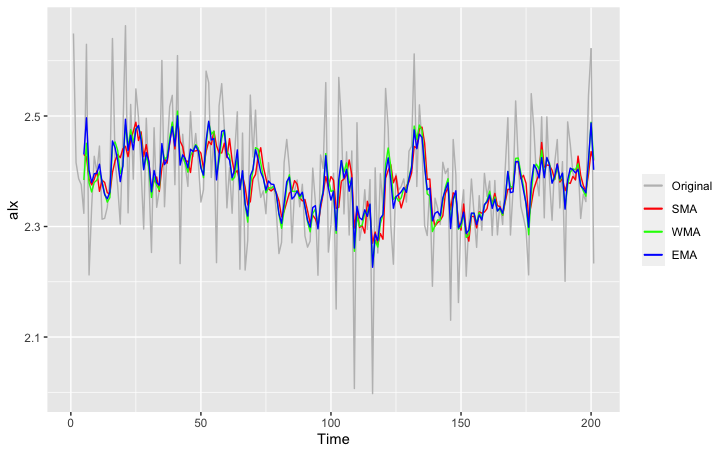
一般在進行穿戴式裝置資料處理時,較常使用的為簡單移動平均,而除了使用smoothing來減小雜訊的干擾之外,另一種處理方法為取特定時間區段之平均值,如:每五秒取一個資料點(即將五秒內的所有資料點取平均),此方法可以有效減低雜訊的影響並大幅減少資料量。
R: 參考
library(TTR)
# 選取其中一段活動訊號(200個資料點),建立dataframe
smooth_df <- data.frame(Time = seq(1,length(dataset2[6657:6857,1]),1), alx = dataset2[6657:6857,1])
# 以每5個資料點進行smoothing,可透過function內的n來做設定
# Simple moving average
smooth_df$sma5_x <- TTR::SMA(dataset2[6657:6857,c(1)], n = 5)
# Weighted moving average
smooth_df$wma5_x <- TTR::WMA(dataset2[6657:6857,c(1)], n = 5)
# Exponential moving average
smooth_df$ema5_x <- TTR::EMA(dataset2[6657:6857,c(1)], n = 5)
# 使用ggplot繪圖
ggplot(smooth_df,aes(x = Time))+
geom_line(aes(y = alx, colour = "Original"))+
geom_line(aes(y = sma5_x, colour = "SMA"))+
geom_line(aes(y = wma5_x, colour = "WMA"))+
geom_line(aes(y = ema5_x, colour = "EMA"))+
scale_colour_manual("", breaks = c("Original", "SMA", "WMA",'EMA'),values = c('grey',"red", "green", "blue"))
Python: 參考
# 選取其中一段活動訊號(200個資料點),建立dataframe
smoothing_data = dataset2.iloc[list(range(6656,6856,1)),[0]]
smoothing_data['Time'] = range(1,201,1)
# 以每5個資料點進行smoothing,可透過function內的n來做設定
# SMA
smoothing_data['SMA'] = smoothing_data['alx'].rolling(window=5).mean()
# WMA
weights = np.array([0.1, 0.2, 0.3, 0.4, 0.5])
sum_weights = np.sum(weights)
smoothing_data['WMA'] = (smoothing_data['alx'].rolling(window=5)
.apply(lambda x: np.sum(weights*x) / sum_weights, raw=False))
# EMA
smoothing_data['EMA'] = smoothing_data['alx'].ewm(span = 5).mean()
# plot
plt.rcParams['figure.figsize'] = 10, 6 #設定圖片大小
smoothing_data.plot(x="Time", y=["alx", "SMA",'WMA','EMA'],kind = 'line')
plt.legend(labels = ['Original','SMA','WMA','EMA'],bbox_to_anchor=(1.0, 1.0))


